
やりたかったこと
今回やりたかったことは以下のとおりです。
- OpenGL ES 3.0を使用
- 入力画像列を順次処理してCPU側で扱える出力画像列を生成
- できるだけ高速に処理
OpenGL ES 3.0を使用することにしたのは、環境面の理由です。ただし、本家OpenGLや他のバージョンのOpenGL ESにも通用する内容かとは思います。入力画像はテクスチャとして入力し、出力画像はOpenGL ES 3.0で描画した結果をglReadPixelsにより読み出します。このときにPBO(Pixel Buffer Object)を使用することでどの程度高速化できるかの検証を行いました。
本記事では、glReadPixelsによる読み出し部分に着目しています。後日、入力側についても検証予定です。
検証のために書いたコード
全体を示すと長くなるので、ポイントとなる2つの関数のみ示します。まず1つ目は描画を行うrender関数です。
void Renderer::render() {
glViewport(0, 0, width, height);
glUseProgram(program);
glActiveTexture(GL_TEXTURE0);
glBindTexture(GL_TEXTURE_2D, texture);
glTexSubImage2D(GL_TEXTURE_2D, 0, 0, 0, width, height, GL_RGBA, GL_UNSIGNED_BYTE, imageData.data());
glUniform1i(glGetUniformLocation(program, "width"), width);
glUniform1i(glGetUniformLocation(program, "height"), height);
glUniform1i(glGetUniformLocation(program, "sampler"), 0);
glEnableVertexAttribArray(0);
glBindBuffer(GL_ARRAY_BUFFER, arrayBuffer);
glVertexAttribPointer(0, 2, GL_FLOAT, GL_FALSE, 0, nullptr);
glBindBuffer(GL_ELEMENT_ARRAY_BUFFER, elementBuffer);
glDrawElements(GL_TRIANGLES, 6, GL_UNSIGNED_BYTE, nullptr);
glBindTexture(GL_TEXTURE_2D, 0);
glBindBuffer(GL_ELEMENT_ARRAY_BUFFER, 0);
glBindBuffer(GL_ARRAY_BUFFER, 0);
if(mode == RenderMode::normal) {
glReadPixels(0, 0, width, height, GL_RGBA, GL_UNSIGNED_BYTE,
outData.data());
}
else if(mode == RenderMode::map) {
// PBOを使用して読み出す
glBindBuffer(GL_PIXEL_PACK_BUFFER, readPbos[idx]);
glReadPixels(0, 0, width, height, GL_RGBA, GL_UNSIGNED_BYTE, 0);
glBindBuffer(GL_PIXEL_PACK_BUFFER, 0);
// idxを進める
// ただし、N=2なので交互にPBOを使用しているだけ
// readOutData関数では今回の描画結果ではなく前回の描画結果を読み出すことになる
idx = (idx + 1) % N;
}
}プログラムは描画要求のためにrender関数を呼んで描画を行います。render関数の中ではglDrawElementsによる描画を行った後、modeというインスタンス変数の値に従ってglReadPixels関数により単純に読み出すかPBOを使って読み出すかを切り替えています。mode == RenderMode::normalの場合であっても読み出した結果をインスタンス内に保持するだけなので、render関数とは別に描画結果をインスタンス外から取り出すための関数を別途用意しています。
void Renderer::readOutData(uint8_t *out) {
if(mode == RenderMode::normal) {
std::copy(outData.cbegin(), outData.cend(), out);
}
else {
// render関数内でインデックスを進めているため、読み出すのは1つ前の描画結果
glBindBuffer(GL_PIXEL_PACK_BUFFER, readPbos[idx]);
auto p = static_cast<uint8_t *>(glMapBufferRange(GL_PIXEL_PACK_BUFFER, 0, width * height * 4, GL_MAP_READ_BIT));
std::copy(p, p + width * height * 4, out);
glUnmapBuffer(GL_PIXEL_PACK_BUFFER);
glBindBuffer(GL_PIXEL_PACK_BUFFER, 0);
}
}readOutData関数もmodeというインスタンス変数の値によって挙動を切り替えています。mode == RenderMode::normalの場合は保持していた描画結果をコピーするだけ、そうでない場合はPBOのデータをマップしたポインタから内容をコピーします。
それぞれの関数にコメントで記載してある通り、PBOを使用する場合は2つあるPBOを順次切り替えながら処理を行っています。PBOを使用するとDMAによる転送を行ってくれるため、その間に別の処理を行うことが出来ますが、その転送にはどうしても時間がかかるため1フレーム分遅延させてからCPU側にコピーすることで転送時間を隠蔽しようとしています。
シェーダーの処理内容は割愛しますが、テクスチャに入力された画像を単にぼかすような処理で今回の検証を行っています。ぼかす際に参照するピクセル数を変えることで次節以降でのシェーダー処理の重さを変えています。
比較した結果
シェーダーの処理内容によっても変わってくるようですが、シェーダー処理がある程度軽い場合にはPBOを使用した方が有意に速いという結果になりました。環境によっても変わってくると思われますので、結果の前にPCのスペックを簡単に記載しておきます。
| 項目 | 内容 |
| CPU | Intel Core i5 1340P |
| GPU | Iris Xe (80EU) |
| メモリ | 16GB |
| OS | Fedora 39 |
ここから比較結果になりますが、シェーダーの処理内容がかなり軽い場合は下記のようになりました。
| フレームレート | |
| PBOなし | 約450fps |
| PBOあり | 約500fps |
少しシェーダーの処理内容を重くしてもやはりPBOありの方が速い結果となりました。
| フレームレート | |
| PBOなし | 約180fps |
| PBOあり | 約210fps |
ですが、さらに重たいシェーダー処理にしてみたところ、速度はほとんど変わらなくなりました。
| フレームレート | |
| PBOなし | 約23fps |
| PBOあり | 約23fps |
GPUからデータを読み出す時間が隠蔽されたとしても描画処理自体にかかる時間が支配的であるためほとんど効果がなかったのだと思われます。ただし、CPUの使用率にはかなりの差がありました。下にCPU使用率の画像を示します。
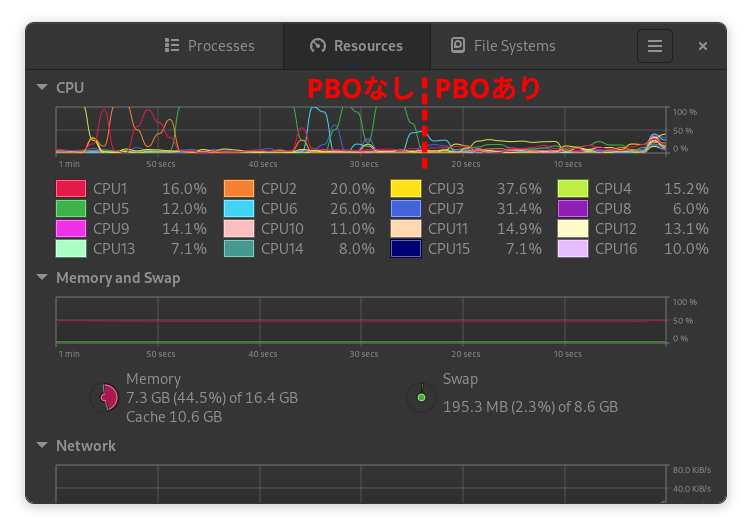
PBOなしの場合はCPUの使用率がかなり高いのに対して、PBOありの場合はCPUの使用率が低くなっています。PBOありの場合はCPUではなくDMAがデータを転送してくれるということで、その分CPUの使用率が低くなってくれるようです。シェーダー処理が軽い場合はここまでの差は出ませんでしたが、やはりPBOありの方がCPU使用率は低い傾向にありました。
まとめ
本記事ではOpenGL ES 3.0で描画した結果をCPU側に読み出す場合にPBOを使用しない場合と使用する場合の速度について確認しました。結果として、描画処理が軽い場合にはPBOを使用する方がスループットが高くなりました。また、描画処理が重い場合はスループットにほとんど差はなかったもののPBOを使用した方がCPU使用率が低くなることが分かりました。他のパターンでの検証も必要かとは思いますが、PBOを使用した方がメリットになる場面は多そうです。


コメント